










はじめに
Webサイトから情報を集めてくるスクレイピングというものを試してみる。
元ネタはgooニュースにあるタレント一覧。ここからタレント一覧を抜き出してみる。

dメニューニュース|NTTドコモ(docomo)のポータルサイト
dメニューニュースはNTTドコモの運営しているニュースサイトです。幅広いニュースを分かりやすく、いち早くお届けしています。話題のニュースや政治、スポーツ、エンタメ、コラムなど情報満載のニュースメディアです。
news.goo.ne.jp
対象とするサイトの構成を確認
はじめにインデックスページ(1)があって、各音のページ(2)にタレント名一覧が表示されている。(2)は「ああ〜あこ」「あさ〜あと」といった具合に複数ページが存在している模様。タレント名を取得できればいいので、対象はこのレベルまで。(さらにリンクをたどるとタレント毎の詳細情報を取得できるけど、今回はそこまで見ない)
<(1)インデックスページ>
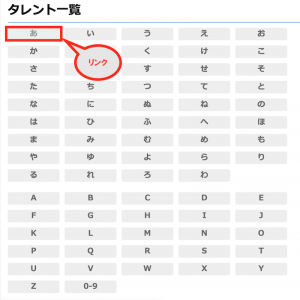
<各音のページ(2)>

対象ページのHTMLを確認
まずインデックスページのHTMLを確認。こんな感じなのでAタグのhref属性を取得できれば良さそう。
<ul class="gn-keyword-list keyword-under-title-order"> <li><a href="/entertainment/talent/j-a/" class="gn-button btn-keyword-list btn-small btn-block">あ</a></li> <li><a href="/entertainment/talent/j-i/" class="gn-button btn-keyword-list btn-small btn-block">い</a></li> <li><a href="/entertainment/talent/j-u/" class="gn-button btn-keyword-list btn-small btn-block">う</a></li> <li><a href="/entertainment/talent/j-e/" class="gn-button btn-keyword-list btn-small btn-block">え</a></li> <li><a href="/entertainment/talent/j-o/" class="gn-button btn-keyword-list btn-small btn-block">お</a></li>
つづけて各音のページのHTMLを確認。こんな感じなので、こちらもインデックスページ同様にAタグのhref属性を取得できれば良さそう。
<ul class="gn-keyword-list keyword-under-order-list"> <li><span class="gn-button btn-keyword-list btn-auto-size btn-block current">ああ~あこ</span></li> <li><a href="/entertainment/talent/j-a-2.html" class="gn-button btn-keyword-list btn-auto-size btn-block">あさ~あと</a></li> <li><a href="/entertainment/talent/j-a-3.html" class="gn-button btn-keyword-list btn-auto-size btn-block">あな~あほ</a></li> <li><a href="/entertainment/talent/j-a-4.html" class="gn-button btn-keyword-list btn-auto-size btn-block">あま~あよ</a></li> <li><a href="/entertainment/talent/j-a-5.html" class="gn-button btn-keyword-list btn-auto-size btn-block">あら~あん</a></li> <li><a href="/entertainment/talent/j-a-6.html" class="gn-button btn-keyword-list btn-auto-size btn-block">その他</a></li> </ul>
実際にコードを書いて抽出してみる
ここまでで、ひとまず対象となるページのURL一覧を作成するコードを書いてみる。
Nokogiriというライブラリが便利そうなので使う。
require 'nokogiri'
require 'open-uri'
base_url = 'https://news.goo.ne.jp'
path = '/entertainment/talent/'
charset = nil
url = base_url +path
html = open(url) do |f|
charset = f.charset
f.read
end
url_list = []
# 最初のインデックスページから50音ごとのリンク先を抽出する
doc = Nokogiri::HTML.parse(html, nil, charset)
doc.xpath('//ul[@class="gn-keyword-list keyword-under-title-order"]').each do |node|
node.css('li > a').each do | first |
path1 = first[:href]
url = base_url + path1
url_list.push( url )
# 50音ごとのページからタレント一覧ページへのリンク先を抽出する
html2 = open(url) do |f|
chaset = f.charset
f.read
end
doc2 = Nokogiri::HTML.parse(html2, nil, charset)
doc2.xpath('//ul[@class="gn-keyword-list keyword-under-order-list"]').each do |node2|
node2.css('li > a').each do | second |
path2 = second[:href]
url = base_url + path2
url_list.push( url )
end
end
end
end
File.open("url_list.txt", "w") do | file |
url_list.each do | url |
file.puts(url)
end
end
結果、こんな感じで一覧が出来る。
| https://news.goo.ne.jp/entertainment/talent/j-a/ https://news.goo.ne.jp/entertainment/talent/j-a-2.html https://news.goo.ne.jp/entertainment/talent/j-a-3.html https://news.goo.ne.jp/entertainment/talent/j-a-4.html https://news.goo.ne.jp/entertainment/talent/j-a-5.html https://news.goo.ne.jp/entertainment/talent/j-a-6.html https://news.goo.ne.jp/entertainment/talent/j-i/ https://news.goo.ne.jp/entertainment/talent/j-i-2.html https://news.goo.ne.jp/entertainment/talent/j-i-3.html https://news.goo.ne.jp/entertainment/talent/j-i-4.html https://news.goo.ne.jp/entertainment/talent/j-i-5.html https://news.goo.ne.jp/entertainment/talent/j-i-6.html 〜 略 〜 |
タレント一覧を抽出する
対象のURL毎にタレント一覧を取得すれば目的達成ですが、まずはHTMLのソースを確認。
ulタグ(class=”gn-thumbs-list thumbs-list-large”)の下にliタグでタレント一覧が並んでいる。
liタグの中身のうち「list-title-news」クラス、「list-news-source」クラスのpタグがそれぞれ”名前”と”よみがな”の模様。
<ul class="gn-thumbs-list thumbs-list-large"> <li><a href="/entertainment/talent/W17-0923.html"> <div class="gn-news-item news-list-item"> <div class="news-item-thumbs"><img src="https://img.news.goo.ne.jp/talent/MW-W17-0923.jpg" alt="" class="thumbs-xx-small"></div> </div> <div class="image-news-block"> <p class="list-title-news margin-bottom5">あぁ~しらき</p> <p class="list-news-source">アァ~シラキ</p> </div> </a></li>
で、コード(かなり適当・・・)
require 'nokogiri'
require 'open-uri'
charset = nil
url_list = []
file = File.open("url_list.txt", "r")
file.each do | text |
url_list.push(text.chomp)
end
file.close
url_list.each do | url |
html = open(url) do |f|
charset = f.charset
f.read
end
url_list = []
doc = Nokogiri::HTML.parse(html, nil, charset)
doc.xpath('//ul[@class="gn-thumbs-list thumbs-list-large"]').each do |node|
name = [] # 名前
kana = [] # よみがな
node.css('li > a > div.image-news-block > p.list-title-news').each do | first |
name.push(first.inner_text)
end
node.css('li > a > div.image-news-block > p.list-news-source').each do | first |
kana.push(first.inner_text)
end
File.open("name_list.csv", "a") do | file |
for cnt in 0..name.length-1 do
name[cnt].gsub!(/\"/, '""')
file.printf("\"%s\",\"%s\"\n", name[cnt], kana[cnt])
end
end
end
end
タレント名の一覧をCSV形式で出力できたので、おしまい。ここに登録されているタレントだけでも25,000人もいるんですね、びっくり。

コメント